Liferay.Design
Articles
Careers
Events
Team
Handbook
Sign In
We are
Liferayʼs global team of
designers.
We're Hiring
What's New
Why Design (Week)?
6 Min Read
8 Tips for Building Stronger Client Relationships
5 Min Read
How AI Is Helping UX
4 Min Read
Resources
Get More
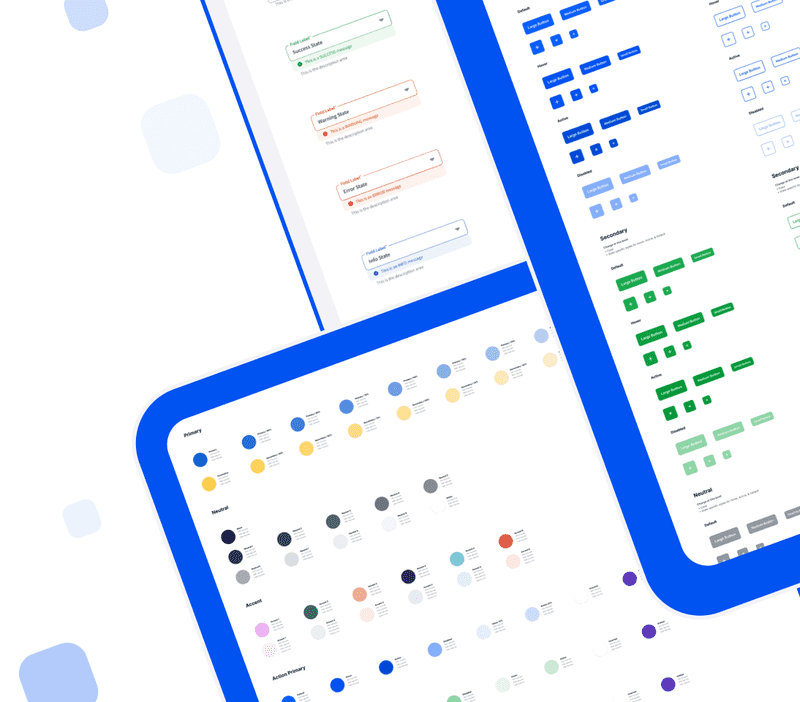
Lexicon Design System
Our open-source system for designing enterprise software
Free Figma Resources
Utilities and components to help you speed up your workflow
Sign up for our monthly newsletter!
Read past issues
Email Address